
在 Amazon EMR on EKS 使用 AWS Fargate 運行你的 Big Data 大數據 Map Reduce 運算
在上一篇內容中,我展示了如何整合 AWS EMR 及 Amazon EKS 以幫助你運行 Spark 進行你的 Big Data 大數據 Map Reduce 運算,如果你想具體了解在一般環境下如何快速建立 Amazon EMR on EKS 的環境,可以參考:一小時內搭建好 Amazon EMR on EKS 運行 Spark on Kuberentes。在這一篇內容,我將基於上篇的執行環境,與你分享如何使用 AWS Fargate 運行你的 Map Reduce 運算。

簡介
AWS Fargate 是什麼?
AWS Fargate 是一種無伺服器運算引擎,適用於搭配 Amazon Elastic Container Service (ECS) 與 Amazon Elastic Kubernetes Service (EKS) 使用的容器。在過去,你會需要顧慮為你的容器部署之前相應的可用運算環境 (例如:我需要先部署 1 臺機器以供我啟動容器) 並且煩惱底層運算機器的擴展。然而,一旦選擇 Fargate 作為運行技術,你只需要專注容器的業務運行 (比如:我需要運行 10 個容器,簡簡單單的就能啟動,不需要顧慮要先運行多少底層運算機器),並可以依照所需資源大小 (CPU / Memory) 以執行時間計費。
Fargate 的執行環境是單獨且隔離的,你的應用資源並不會與其他在雲端上的客戶共享並被存取。使用這種運行模式,你也無需煩惱定期需要更新你底層的作業系統核心、軟體、漏洞修補以確保安全性和合規。
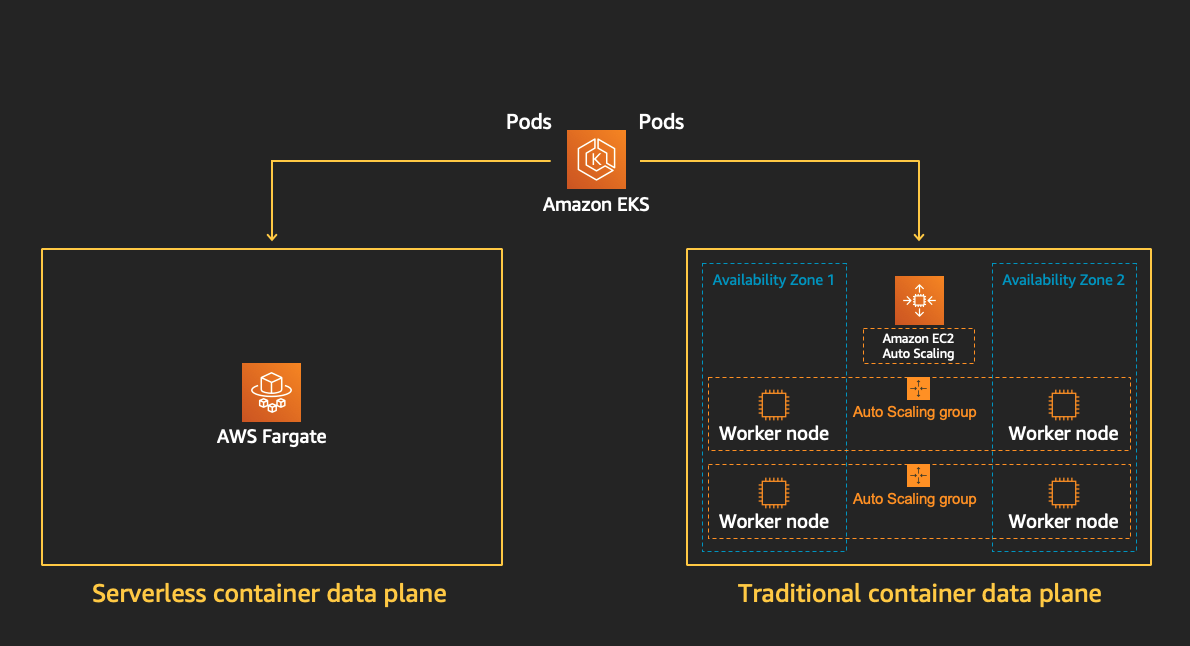
概覽 (Overview)
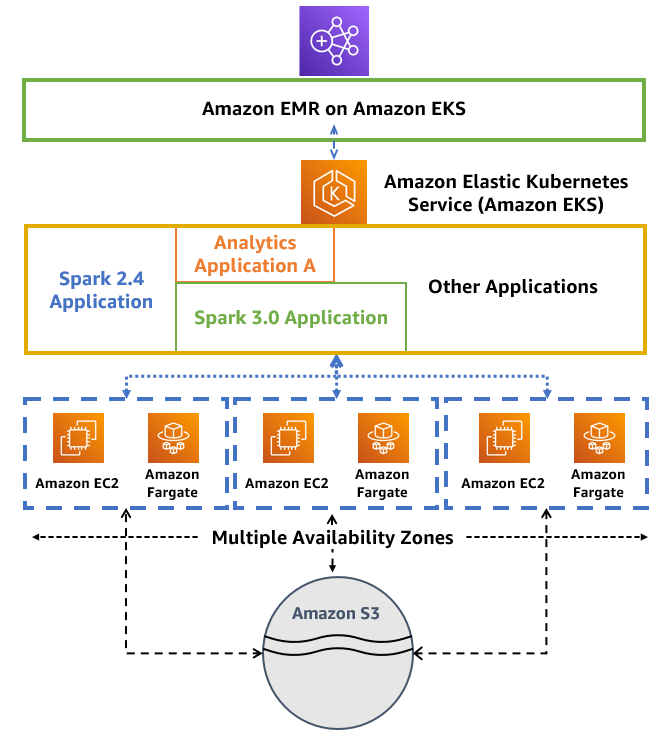
基本上與上一篇 一小時內搭建好 Amazon EMR on EKS 運行 Spark on Kuberentes 並未有太大的出入,最顯著的差異為將工作負載轉移至 AWS Fargate 上運行。
在這篇內容中,我們將會為 Amazon EKS 設置相應的 Kubernetes namespace 並設置 Fargate Profile,以供任何在特定 Kubernetes namespace 中啟動,在 Amazon EMR 無需進行過多複雜的設置。
Fargate Profile
在 Amazon EKS 中提供了 AWS Fargate Profile。這項配置就像是一個設定檔,如果要將運行於 Amazonn EKS 中的 Pod 採用 Fargate 技術運行,則需要定義一個 Fargate Profile,指定哪些 Pod 應在啟動時使用 Fargate。Fargate Profile 可以宣告哪些 Pod 要在 Fargate 上執行。
在這個配置中,會有一個 Selector,用於指定特定的 Kubernetes namespace 或是特定 Kubernetes Labels 採用 Fargate 技術運行 Pod。如果要 Pod 符合 Fargate Profile 中的任一 Selector,則該 Pod 會用 Fargate 技術運行。
開始動手做
預先準備工作
- 擁有 EKS Cluster
在上一篇內容中,提到了使用 eksctl 命令建立一個 EKS Cluster:
eksctl create cluster --name emr-eks-demo --nodes 3 --region us-east-1
然而,這樣的設置預設會建立 3 個 EC2 instance 作為 Worker Node,如果你想要將所有的負載及工作完全都使用 AWS Fargate 採無伺服器技術運行,你可以改採使用 --fargate 選項建立 EKS Cluster:
(Option) 完全運行基於 AWS Fargate 為技術的 EKS Cluster
$ eksctl create cluster --name emr-eks-demo --region us-east-1 --fargate
2021-05-13 01:40:28 [ℹ] eksctl version 0.38.0
2021-05-13 01:40:28 [ℹ] using region us-east-1
2021-05-13 01:40:28 [ℹ] setting availability zones to [us-east-1c us-east-1a]
2021-05-13 01:40:28 [ℹ] subnets for us-east-1c - public:192.168.0.0/19 private:192.168.64.0/19
2021-05-13 01:40:28 [ℹ] subnets for us-east-1a - public:192.168.32.0/19 private:192.168.96.0/19
2021-05-13 01:40:28 [ℹ] using Kubernetes version 1.18
2021-05-13 01:40:28 [ℹ] creating EKS cluster "emr-eks-demo" in "us-east-1" region with Fargate profile
2021-05-13 01:40:28 [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-east-1 --cluster=emr-eks-demo'
2021-05-13 01:40:28 [ℹ] CloudWatch logging will not be enabled for cluster "emr-eks-demo" in "us-east-1"
2021-05-13 01:40:28 [ℹ] you can enable it with 'eksctl utils update-cluster-logging --enable-types={SPECIFY-YOUR-LOG-TYPES-HERE (e.g. all)} --region=us-east-1 --cluster=emr-eks-demo'
2021-05-13 01:40:28 [ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "emr-eks-demo" in "us-east-1"
2021-05-13 01:40:28 [ℹ] 2 sequential tasks: { create cluster control plane "emr-eks-demo", 2 sequential sub-tasks: { 2 sequential sub-tasks: { wait for control plane to become ready, create fargate profiles }, create addons } }
2021-05-13 01:40:28 [ℹ] building cluster stack "eksctl-emr-eks-demo-cluster"
2021-05-13 01:40:30 [ℹ] deploying stack "eksctl-emr-eks-demo-cluster"
...
建立完成後,若正確建立完全運行基於 AWS Fargate 為技術的 EKS Cluster,你可以注意到會有 Fargate Node 自動地被註冊至 EKS Cluster 中:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
fargate-ip-192-168-124-153.ec2.internal Ready <none> 34h v1.18.9-eks-866667
fargate-ip-192-168-80-190.ec2.internal Ready <none> 34h v1.18.9-eks-866667
部分 Amazon EMR 配置與上一篇內容大同小異,你也可以參考該篇內容,以取得更多細節互相參考。
Step 1. 建立一個新的 Fargate Profile
在 Kubernetes Cluster 中建立一個用於計算 EMR 任務的 namespace (Kubernetes namespace),為了方便辨識都是採用 AWS Fargate 技術運行,我將其命名為 emr-fargate-job
kubectl create ns emr-fargate-job
Option 1. 使用 AWS Console
你可以參考以下步驟以圖形化介面為你的 EKS Cluster 設置 Fargate Profile:
- 開啟 EKS Console 並選擇你的 EKS Cluster
- 在你的 EKS Cluster 中,找到 Compute 頁籤底下的 Fargate Profiles,並選擇 Add Fargate Profile
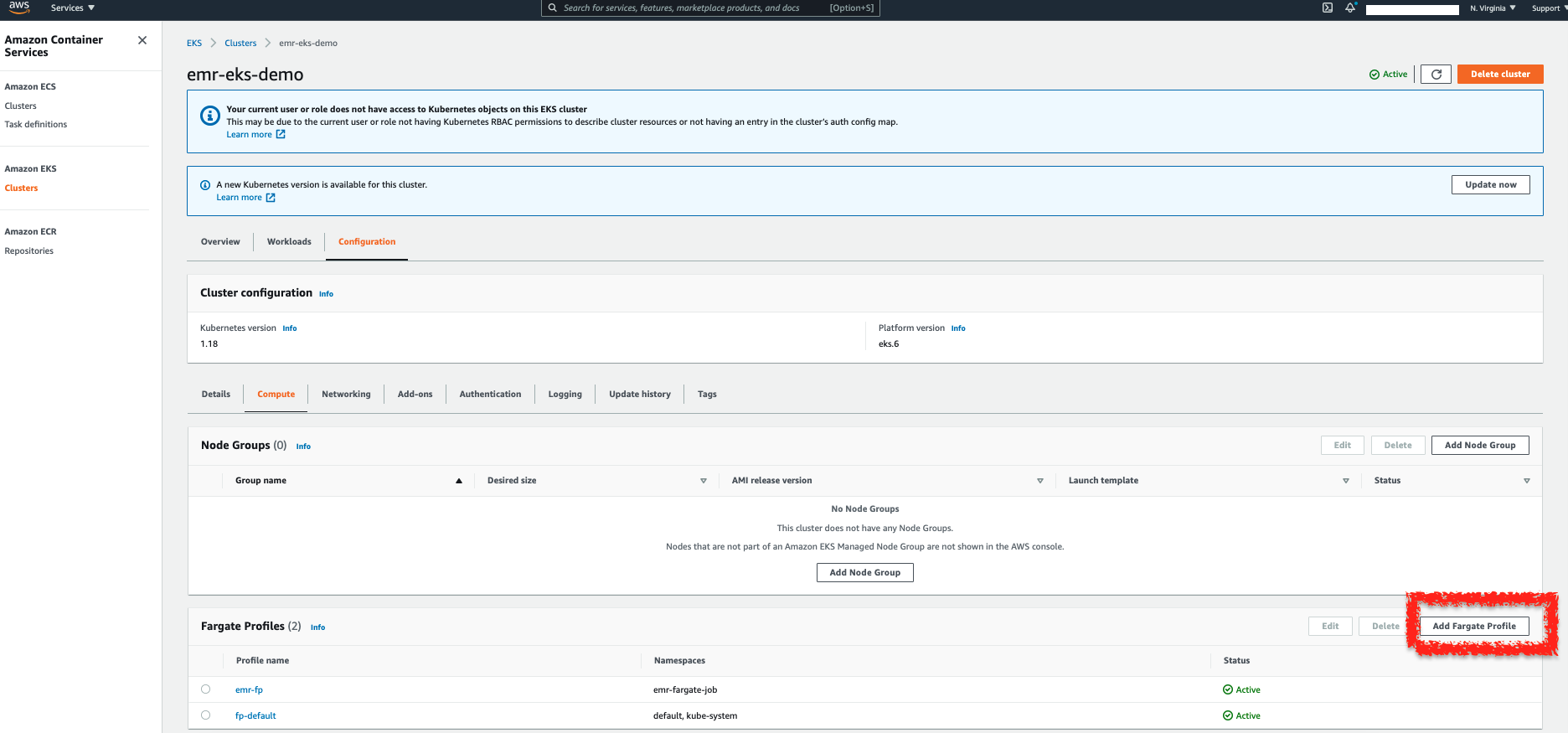
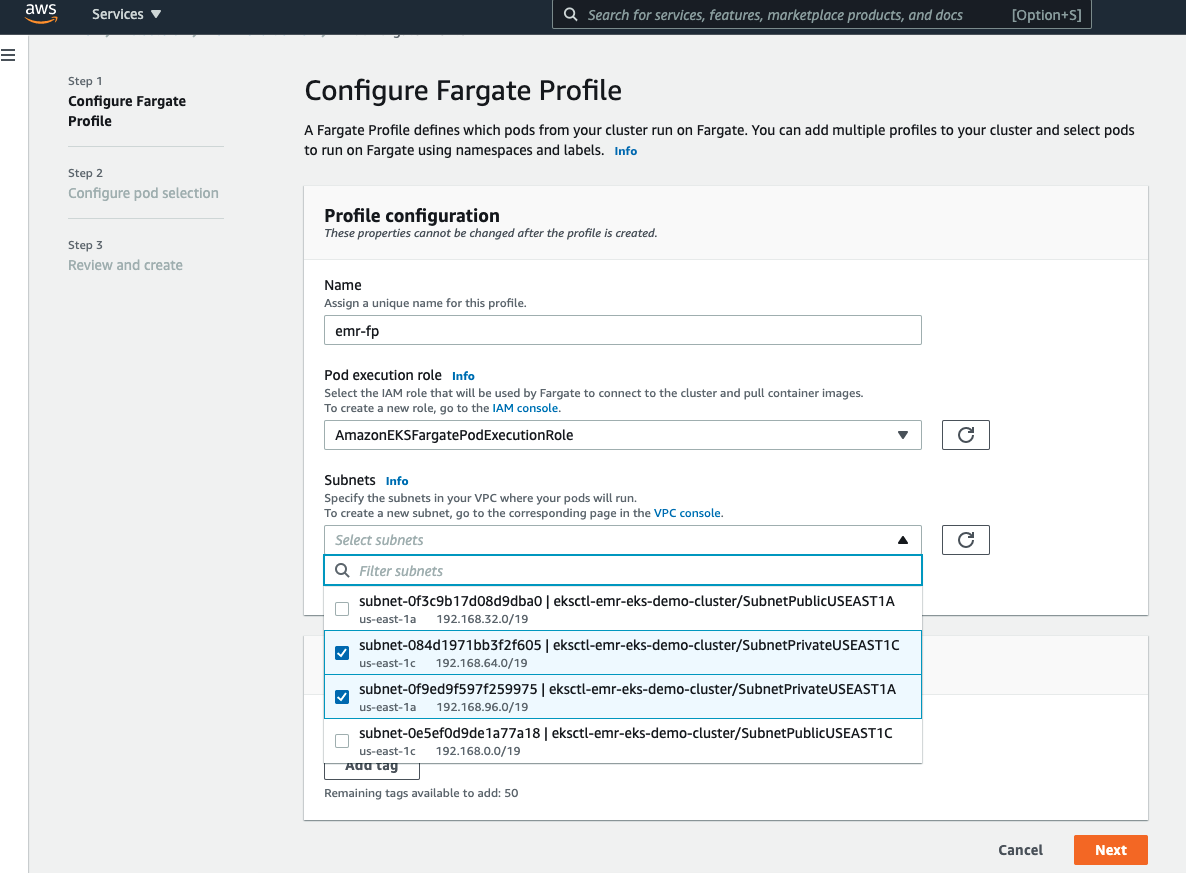
- 設定你的 Fargate Profile:
- Name:
emr-fp(可以設置你容易辨識的名稱) - Pod execution role:
AmazonEKSFargatePodExecutionRole(請參考下面有關AmazonEKSFargatePodExecutionRole的註解) - Subnets: (選擇你的 subnet。請注意目前使用 Fargate 技術運行的 Pod 僅支持 Private subnet,你的 subnet 會需要採用 NAT Gateway,這個如果你使用 eksctl 建立你的集群會,不用煩惱太多,請選擇使用 Private subnet)
- Name:
- 設定 Selector,如此一來運行在這個 namespace 的 Pod 都可以採用 AWS Fargate 技術運行:
- Namespace:
emr-fargate-job(指定使用後續運行 Job 的 Kubernetes namespace)
- Namespace:
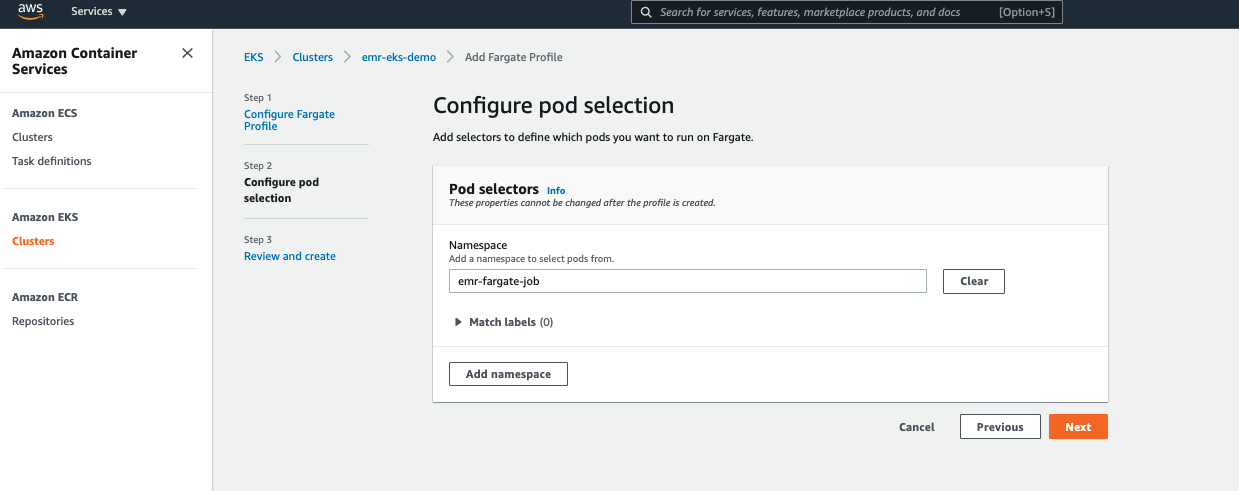
- 檢視你的設置是否有誤,並且按下 Create:
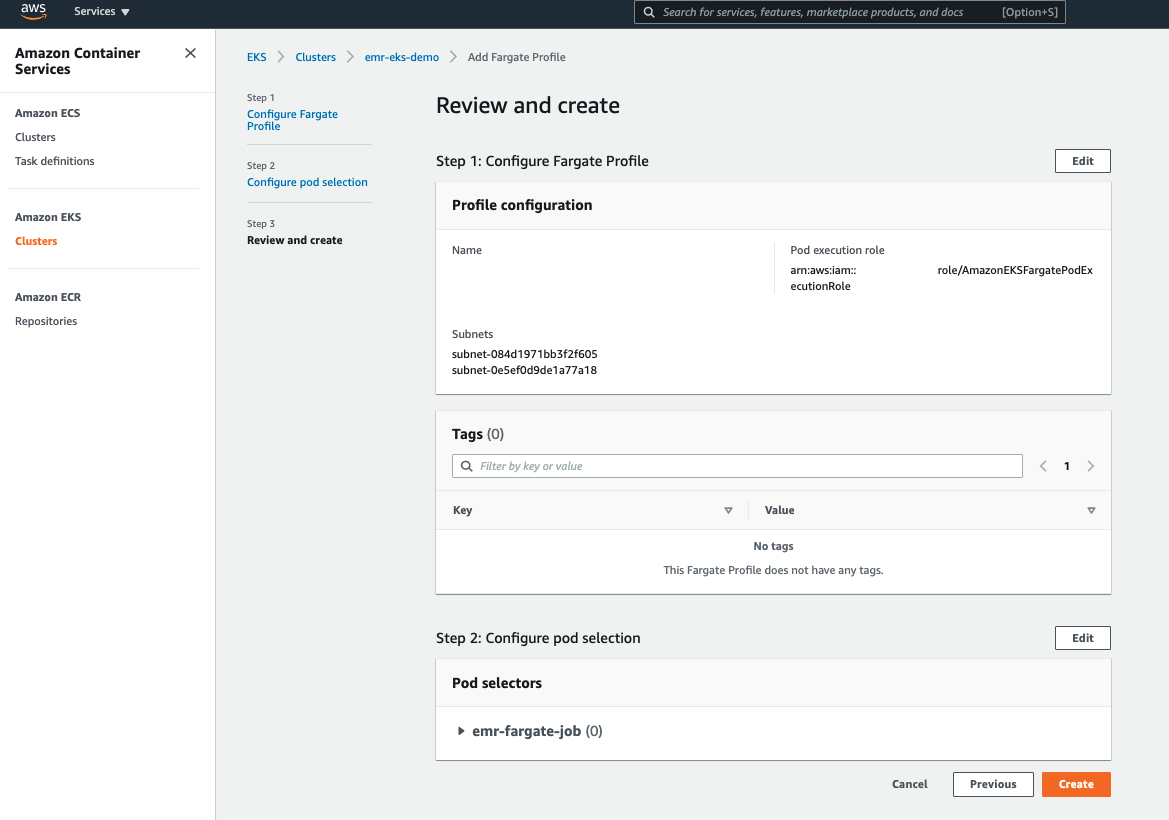
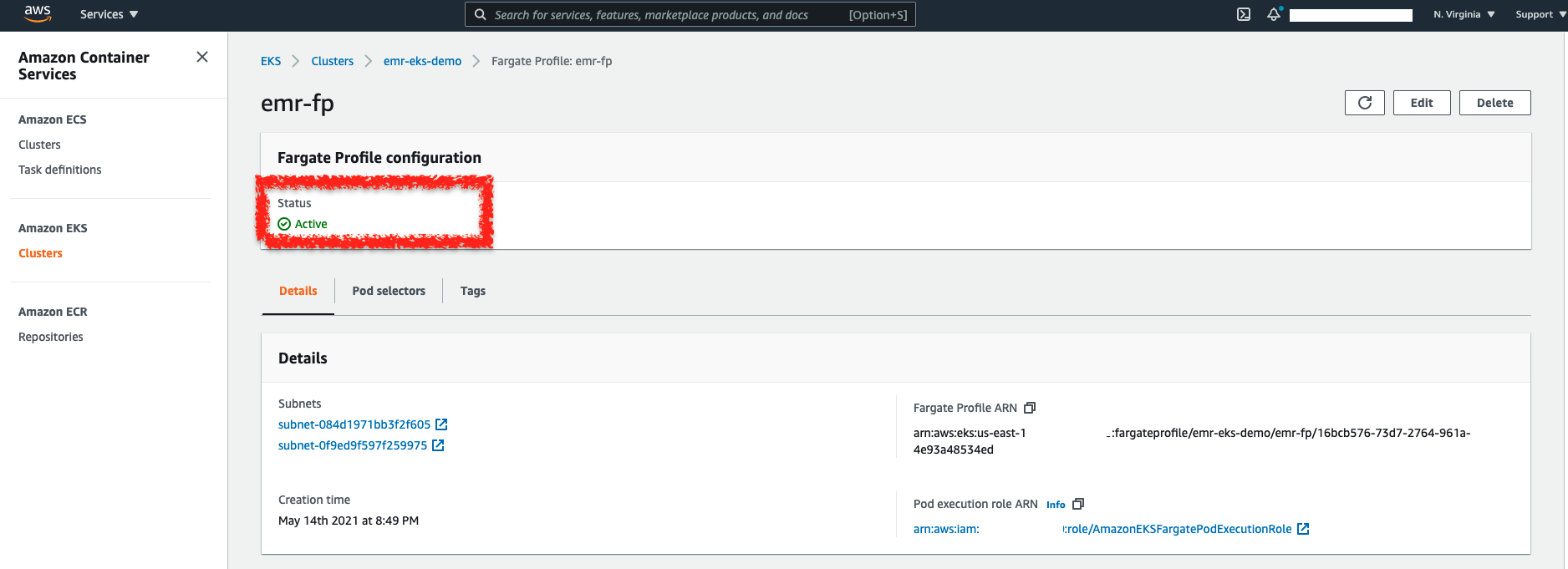
開始建立後,你可以在前面的 EKS Console 點擊你的 Fargate Profile,一旦狀態變更為 ACTIVE 即是建立成功:
Option 2. 使用 AWS CLI
若你慣於使用 AWS CLI,你可以參考以下命令以為你的 EKS Cluster 設置 Fargate Profile:
aws eks create-fargate-profile \
--fargate-profile-name emr-fp \
--cluster-name emr-eks-demo \
--pod-execution-role-arn arn:aws:iam::11122233344:role/AmazonEKSFargatePodExecutionRole \
--selectors namespace=emr-fargate-job
[output]
{
"fargateProfile": {
"fargateProfileName": "emr-fp",
"fargateProfileArn": "arn:aws:eks:us-east-1:11122233344:fargateprofile/emr-eks-demo/emr-fp/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"clusterName": "emr-eks-demo",
"createdAt": "2021-05-14T12:49:42.323000+00:00",
"podExecutionRoleArn": "arn:aws:iam::11122233344:role/AmazonEKSFargatePodExecutionRole",
"subnets": [
"subnet-084d1971bb3f2f605",
"subnet-0f9ed9f597f259975"
],
"selectors": [
{
"namespace": "emr-fargate-job"
}
],
"status": "CREATING",
"tags": {}
}
}
註:一般來說 AmazonEKSFargatePodExecutionRole 在你過去有建立過 EKS on Fargate 的操作會存在,如果你的帳戶並沒有,可以參考這篇文件建立。
Step 2. 為 Amazonn EMR 賦予操作 Kubernetes Cluster 的權限
建立後,下一步便是為 Amazon EMR 賦予操作該 namespace 相應的權限 (Amazon EMR 將會使用 Service Linked Role AWSServiceRoleForAmazonEMRContainers 操作集群),因此,這個動作將會使用 eksctl 建立 Amazon EMR 操作 EKS Cluster 所必須的 RBAC 相關權限,如此一來,使用 Amazon EMR 送出運算任務時,才能正確的在 EKS Cluster 中建立相關的資源 (例如:Job, Pod, Secret … 等等):
eksctl create iamidentitymapping \
--cluster emr-eks-demo \
--namespace emr-fargate-job \
--service-name "emr-containers"
在完成設置後,需要更新 EMR 操作 Job Execution Role 相應的 Trust Policy (配置 Job Execution Role 的相關步驟和啟用 OIDC Provider 可以參考前一篇 Step 3 & Step 4. 建立 EMR 可以操作的角色 (IAM Role) 並更新對應的權限):
eksctl create iamserviceaccount \
--name emr-on-eks-job-execution-role \
--namespace emr-fargate-job \
--cluster emr-eks-demo \
--attach-policy-arn arn:aws:iam::11122233344:policy/EMR-EKS-JobExecutionRolePolicy \
--approve \
--override-existing-serviceaccounts
獲取 IAM Role 名稱 (arn:aws:iam::11122233344:role/eksctl-emr-eks-demo-addon-iamserviceaccount-Role1-1681FO4LQG4QC)。請注意是 emr-fargate-job namespace:
kubectl describe sa/emr-on-eks-job-execution-role -n emr-fargate-job
Name: emr-on-eks-job-execution-role
Namespace: emr-fargate-job
Labels: <none>
Annotations: eks.amazonaws.com/role-arn: arn:aws:iam::11122233344:role/eksctl-emr-eks-demo-addon-iamserviceaccount-Role1-1681FO4LQG4QC
Image pull secrets: <none>
Mountable secrets: emr-on-eks-job-execution-role-token-jbjxp
Tokens: emr-on-eks-job-execution-role-token-jbjxp
Events: <none>
在取得 IAM Role ARN 後,請再套用命令前,將以下更換為你相應的 IAM Role 名稱 (<eksctl-emr-eks-demo-addon-iamserviceaccount-Role1-1681FO4LQG4QC>):
aws emr-containers update-role-trust-policy \
--cluster-name emr-eks-demo \
--namespace emr-fargate-job \
--role-name <eksctl-emr-eks-demo-addon-iamserviceaccount-Role1-1681FO4LQG4QC>
Step 3. 將 Amazon EKS 註冊至 Amazon EMR 作為可運算對象 (Virtual Cluster)
使用以下命令於 EMR 建立一個 Virtual Cluster (可以將 my_emr_virtual_cluster 更換為你容易識別的名稱):
aws emr-containers create-virtual-cluster \
--name emr_fargate_virtual_cluster \
--container-provider '{
"id": "emr-eks-demo",
"type": "EKS",
"info": {
"eksInfo": {
"namespace": "emr-fargate-job"
}
}
}'
[output]
{
"id": "wuenyscuofnz53vy5m39g2n10",
"name": "emr_fargate_virtual_cluster",
"arn": "arn:aws:emr-containers:us-east-1:11122233344:/virtualclusters/wuenyscuofnz53vy5m39g2n10"
}
Step 4. 運行 Spark Job!
(套用上述設置運行 Spark Job 的一項使用範例)
aws emr-containers start-job-run \
--virtual-cluster-id wuenyscuofnz53vy5m39g2n10 \
--name pi-job \
--execution-role-arn arn:aws:iam::11122233344:role/eksctl-emr-eks-demo-addon-iamserviceaccount-Role1-1681FO4LQG4QC \
--release-label emr-6.2.0-latest \
--job-driver '{"sparkSubmitJobDriver": {"entryPoint": "local:///usr/lib/spark/examples/src/main/python/pi.py", "sparkSubmitParameters": "--conf spark.executor.instances=1 --conf spark.executor.memory=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1"}}' \
--configuration-overrides '{"applicationConfiguration": [{"classification": "spark-defaults", "properties": {"spark.driver.memory": "2G"}}], "monitoringConfiguration": {"cloudWatchMonitoringConfiguration": {"logGroupName": "emr-on-eks-log", "logStreamNamePrefix": "pi"}, "persistentAppUI":"ENABLED", "s3MonitoringConfiguration": {"logUri": "s3://My-EMR-Log-Bucket" }}}'
[output]
{
"id": "00000002ubarp3tg0ne",
"name": "pi-job",
"arn": "arn:aws:emr-containers:us-east-1:11122233344:/virtualclusters/wuenyscuofnz53vy5m39g2n10/jobruns/00000002ubarp3tg0ne",
"virtualClusterId": "wuenyscuofnz53vy5m39g2n10"
}
送出任務後,若一切正確配置,你可以在 emr-fargate-job 中找到你的 Pod,並且,稍待幾分鐘,Fargate 將會幫助你調度並部署新的 Fargate Node 供其運算:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
fargate-ip-192-168-118-40.ec2.internal NotReady <none> 6s v1.18.9-eks-866667
...
$ kubectl get pods -n emr-fargate-job
NAME READY STATUS RESTARTS AGE
00000002ubatqrom028-87b7k 3/3 Running 0 3m32s
spark-00000002ubatqrom028-driver 0/2 Pending 0 44s
Name: 00000002ubatqrom028-87b7k
Namespace: emr-fargate-job
Priority: 2000001000
PriorityClassName: system-node-critical
Node: fargate-ip-192-168-118-40.ec2.internal/192.168.118.40
當 Job 完成運算,你可以在 EMR Console 中得知該任務完成的變化。
總結
在這篇內容中,我展示了如何使用 Amazon EMR + Amazon EKS 並使用 AWS Fargate 與你分享快速部署一個範例的運行無伺服器的執行架構,運行大數據運算工作,能夠協助你在配置時具體了解其流程。
由於很多人對於 AWS Fargate 可能十分陌生,希望上述的內容,能夠幫助你了解並幫助你成功運行這樣的解決方案。如果你覺得這樣的內容有幫助,可以在底下按個 Like / 留言讓我知道,並且分享給有需要搭建環境的人,幫助他們快速了解 AWS Fargate 的神奇威力!
看更多系列文章
Share on
Twitter Facebook LinkedInIs that useful? Let me know or buy me a coffee
 一次性支持 (ECPay)
一次性支持 (ECPay)


Leave a comment