
[AWS][EKS] Zero downtime deployment(RollingUpdate) when using AWS Load Balancer Controller on Amazon EKS
This article is describing the thing you need to aware when using ALB Ingress Controller (AWS Load Balancer Controller) to do deployment and prevent 502 errors.
What’s AWS Load Balancer Controller (legacy ALB Ingress Controller)
Kubernetes doesn’t involve the Application Load Balancer (ALB) deployment in the native implementation for using Kubernetes service object with type=LoadBalancer. Therefore, if you would like to expose your container service with Application Load Balancer (ALB) on EKS, it is recommended to integrate with AWS Load Balancer Controller (In the past, it was ALB Ingress Controller when it firstly initiated by CoreOS and Ticketmaster). This controller make it possible to manage have load balancers with Kubernetes deployment.
Below is showing an overview diagram that describing the controller workflow:

- (1) The controller watches for ingress events from the API server.
- (2) An ALB (ELBv2) is created in AWS for the new ingress resource. This ALB can be internet-facing or internal.
- (3) Target Groups are created in AWS for each unique Kubernetes service described in the ingress resource.
- (4) Listeners are created for every port detailed in your ingress resource annotations.
- (5) Rules(ELB Listener Rules) are created for each path specified in your ingress resource. This ensures traffic to a specific path is routed to the correct Kubernetes Service.
Note: AWS ALB Ingress Controller is replaced, while rename it to be “AWS Load Balancer Controller” with several new features coming out. For more detail, please refer the GitHub project - kubernetes-sigs/aws-alb-ingress-controller
How to deploy Kubernetes with AWS Load Balancer Controller?
Using Application Load Balancer as example, when running the controller, AWS Load Balancer Controller will be deployed as a Pod running on your worker node while continously monitor/watch your cluster state. Once there have any request for Ingress object creation, AWS Load Balancer Controller will help you to manage and create Application Load Balancer resource. Here is a part of example for v1.1.8 deployment manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: alb-ingress-controller
name: alb-ingress-controller
namespace: kube-system
spec:
selector:
matchLabels:
app.kubernetes.io/name: alb-ingress-controller
template:
metadata:
labels:
app.kubernetes.io/name: alb-ingress-controller
spec:
containers:
- name: alb-ingress-controller
args:
# Setting the ingress-class flag below ensures that only ingress resources with the
# annotation kubernetes.io/ingress.class: "alb" are respected by the controller. You may
# choose any class you'd like for this controller to respect.
- --ingress-class=alb
# REQUIRED
# Name of your cluster. Used when naming resources created
# by the ALB Ingress Controller, providing distinction between
# clusters.
# - --cluster-name=devCluster
# AWS VPC ID this ingress controller will use to create AWS resources.
# If unspecified, it will be discovered from ec2metadata.
# - --aws-vpc-id=vpc-xxxxxx
# AWS region this ingress controller will operate in.
# If unspecified, it will be discovered from ec2metadata.
# List of regions: http://docs.aws.amazon.com/general/latest/gr/rande.html#vpc_region
# - --aws-region=us-west-1
image: docker.io/amazon/aws-alb-ingress-controller:v1.1.8
serviceAccountName: alb-ingress-controller
The deployment basically will run a copy of ALB Ingress Controller (pod/alb-ingress-controller-xxxxxxxx-xxxxx) in kube-system:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system pod/alb-ingress-controller-5fd8d5d894-8kf7z 1/1 Running 0 28s
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system deployment.apps/alb-ingress-controller 1/1 1 1 3m48s
Since v2, the controller added lots of different custom resources and enhancements. But the core deployment still preserve many thing that mentioned in this post. Depending on your environment, the default and suggested installation steps may also involve the configuration of IRSA (IAM Role for Service Account) to grant permission for the AWS Load Balancer Controller Pods in order to operate AWS resources (e.g. ELB), so it is recommended to take a look official documentation to help you quickly understand how to install the controller:
In addition, the service can be deployed as Ingress Object. For example, if you tried to deploy the simple 2048 application:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.8/docs/examples/2048/2048-namespace.yaml
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.8/docs/examples/2048/2048-deployment.yaml
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.8/docs/examples/2048/2048-service.yaml
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.8/docs/examples/2048/2048-ingress.yaml
The file 2048-ingress.yaml is mentioning the annotations, spec in format that supported by ALB Ingress Controller can recognize (Before Kubernetes 1.18):
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: "2048-ingress"
namespace: "2048-game"
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
labels:
app: 2048-ingress
spec:
rules:
- http:
paths:
- path: /*
backend:
serviceName: "service-2048"
servicePort: 80
Before the IngressClass resource and ingressClassName field were added in Kubernetes 1.18, Ingress classes were specified with a kubernetes.io/ingress.class annotation on the Ingress. So right now, you should see the ingress specification will be defined as below if you are using controller version v2.x:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/v2.4.1/docs/examples/2048/2048_full.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: game-2048
name: ingress-2048
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service-2048
port:
number: 80
The ingress object will construct ELB Listeners according rules and forward the connection to the corresponding backend(serviceName), which match the group of service service-2048, any traffic match the rule /* will be routed to the group of selected Pods. In this case, Pods are exposed on the worker node based on type=NodePort:
Here is the definition of this Kubernetes service:
apiVersion: v1
kind: Service
metadata:
name: "service-2048"
namespace: "2048-game"
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
type: NodePort
selector:
app: "2048"
So … what’s the problem?
Zero downtime deployment is always a big challenge for DevOps/Operation team when running any kind of business. When you try to apply the controller as a solution to expose your service, it has a couple of things need to take care due to the behavior of Kubernetes, ALB and AWS Load Balancer Controller. To achieve zero downtime, you need to consider many perspectives, some new challenges will also popup when you would like to roll out the new deployment for your Pods with AWS Load Balancer Controller.
Let’s use the 2048 game as example to describe the scenario when you are trying to roll out a new version of your container application. In my environment, I have:
- A Kubernetes service
service/service-2048usingNodePortto expose the service - The deployment also have 5 copy of Pods for 2048 game, which is my backend application waiting for connections forwarding by Application Load Balancer (ALB)
NAMESPACE NAME READY STATUS RESTARTS AGE
2048-game pod/2048-deployment-58fb66554b-2f748 1/1 Running 0 53s
2048-game pod/2048-deployment-58fb66554b-4hz5q 1/1 Running 0 53s
2048-game pod/2048-deployment-58fb66554b-jdfps 1/1 Running 0 53s
2048-game pod/2048-deployment-58fb66554b-rlpqm 1/1 Running 0 53s
2048-game pod/2048-deployment-58fb66554b-s492n 1/1 Running 0 53s
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
2048-game service/service-2048 NodePort 10.100.53.119 <none> 80:30337/TCP 52s
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
2048-game deployment.apps/2048-deployment 5/5 5 5 53s
And for sure, once the controller correctly set up and provision the ELB resource, the full domain of ELB also will be recorded to the Ingress object:
$ kubectl get ingress -n 2048-game
NAME HOSTS ADDRESS PORTS AGE
2048-ingress * xxxxxxxx-2048game-xxxxxxxx-xxxx-xxxxxxxxx.ap-northeast-1.elb.amazonaws.com 80 11m
I can use the DNS name as endpoint to visit my container service:
$ curl -s xxxxxxxx-2048game-xxxxxxxx-xxxx-xxxxxxxxx.ap-northeast-1.elb.amazonaws.com | head
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>2048</title>
<link href="style/main.css" rel="stylesheet" type="text/css">
<link rel="shortcut icon" href="favicon.ico">
...
This application can be any kind of critical service you are running. As a administrator, SRE (Site Reliability Engineer), member of operation team or a DevOps engineer, the goal and your duty is: we always try to ensure the service can run properly without any issue and no interruption (Sometimes it means good sleep). That’s why people really gets hand dirty and maintain the regular operation usually don’t like to adopt service change, because it generally means unstable.
No matter you don’t want to change, with any new business requests, you still can face the challenges like: your developers are saying that “Oh! we need to upgrade the application”, “we are going to roll out a bug fix”, “the new feature is going to be online”, no one can one hundred percent guarantees the service can run properly if any changes applied, because system usually has its limitation and trade-off. Any service downtime can lead anyone of stakeholders(users, operation team or leadership) unhappy.
However, the question is that can we better to address these problem once we know the limitation and its behavior? Some people in Taiwan will also consider to put Kuai Kuai on the workstation because they believe it can make service happy, but I am not very obsessed with this method, so in the following section I will try to walk through more realistic logic and phenomena by using the 2048 game as my sample service.
I am going to use a simple loop trick to continously access my service via the endpoint xxxxxxxx-2048game-xxxxxxxx-xxxx-xxxxxxxxx.ap-northeast-1.elb.amazonaws.com to demonstrate a scenario: This is a popular web service and we always have customer need to access it. (e.g. social media platform, bitcoin trading platform or any else, we basically have zero tolerance for any service downtime as it can impact our revenue.), as below:
$ while true;do ./request-my-service.sh; sleep 0.1; done
HTTPCode=200_TotalTime=0.010038
HTTPCode=200_TotalTime=0.012131
HTTPCode=200_TotalTime=0.005366
HTTPCode=200_TotalTime=0.010119
HTTPCode=200_TotalTime=0.012066
HTTPCode=200_TotalTime=0.005451
HTTPCode=200_TotalTime=0.010006
HTTPCode=200_TotalTime=0.012084
HTTPCode=200_TotalTime=0.005598
HTTPCode=200_TotalTime=0.010086
HTTPCode=200_TotalTime=0.012162
HTTPCode=200_TotalTime=0.005278
HTTPCode=200_TotalTime=0.010326
HTTPCode=200_TotalTime=0.012193
HTTPCode=200_TotalTime=0.005347
...
Meanwhile, I am using RollingUpdate strategy in my Kubernetes deployment strategy with maxUnavailable=25%, which means, when Kubernetes need to update or patch(Like update the image or environment variables), the maximum number of unavailable Pods cannot exceed over 25% as well as it ensures that at least 75% of the desired number of Pods are up (only replace 1-2 Pods if I have 5 copies at the same time):
apiVersion: apps/v1
kind: Deployment
metadata:
name: 2048-deployment
namespace: 2048-game
spec:
...
selector:
matchLabels:
app: "2048"
...
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
Scenario: Rolling the new container image to existing container application with potential service downtime
When rolling the new version of my container application (for example, I update my deployment by replacing the container image with the new image nginx), it potentially can have a period of time that can return HTTP Status Code 502 error in my few hits:
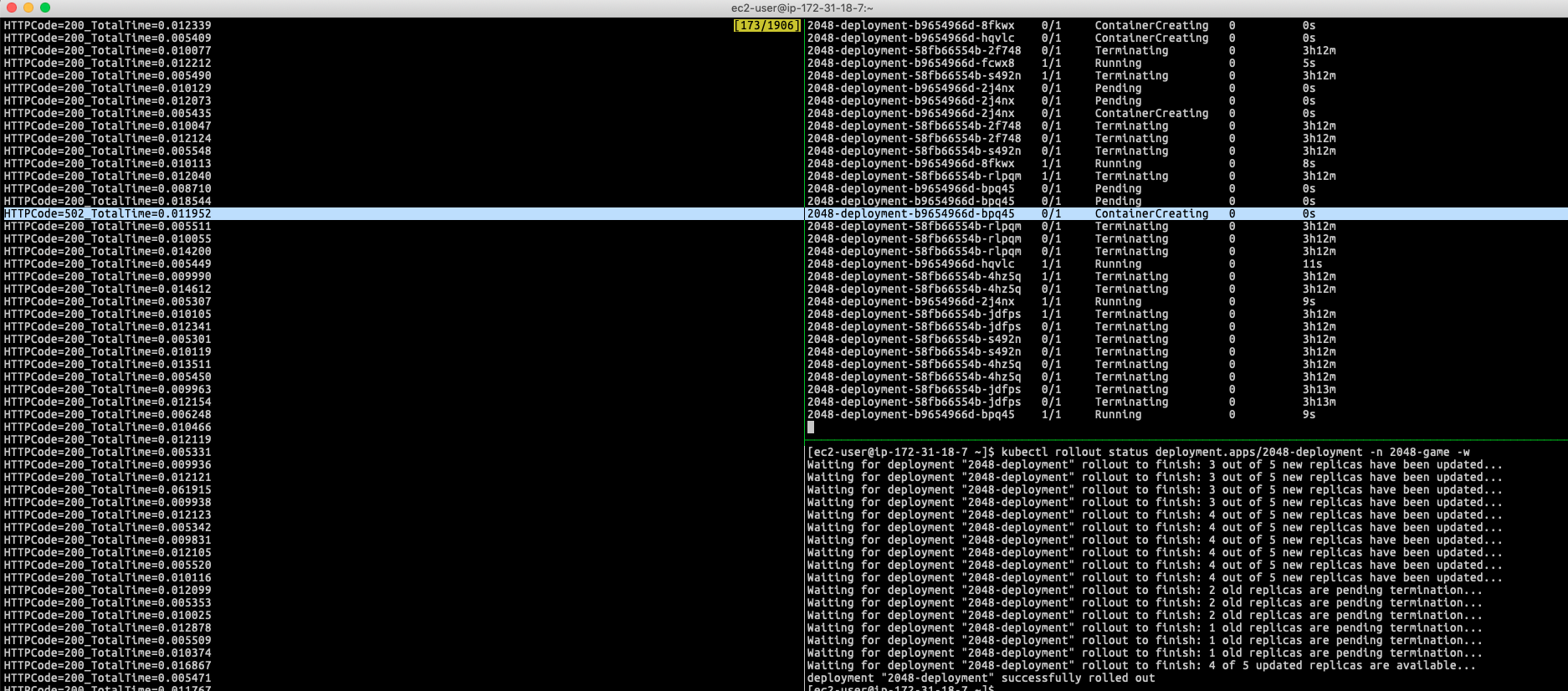
If you are specifying the controller to use instance mode to register targets(Pods) to your ELB Target Group, it will use worker nodes’ instance ID and expose your service in that ELB target group with Kubernetes NodePort. In this case, the traffic will follow the Kubernetes networking design to do second tier of transmission according to externalTrafficPolicy defined in the Kubernetes Service object (No matter using externalTrafficPolicy=Cluster or externalTrafficPolicy=Local).
Due to the controller only care about to register Worker Node to the ELB target group, so if the scenario doesn’t involve the worker node replacement, the case basically have miniumun even no downtime(expect that it is rare to have downtime if the Kubernetes can perfectly handle the traffic forwarding); however, this is not how real world operate, few seconds downtime still can happen potentially due to the workflow below:
This is the general workflow when the client reach out to the service endpoint (ELB) and how was traffic goes
Client ----> ELB ----> Worker Node (iptables) / In this step it might be forwarded to other Worker Node ----> Pod
So, in these cases, you can see the downtime:
- (1) The client established the connection with ELB, ELB is trying to forward the request to the backend (the Worker Node), but the Worker Node is not ready to serve the Pod.
- (2) Follow the iptables rules, the traffic be forwarded to the Pod just terminated due to RollingUpdate (Or the Pod just got the in-flight reqeust but immediately need to be terminated, the Pod flip to
Terminatingstate. It haven’t response back yet, caused the ELB doesn’t get the response from Pod.) - (3) ELB established connection with the Worker Node-1, once the packet enter into the Worker Node-1, it follows the iptables then forward it to the Pod running on Worker Node-2 (jump out the current worker node), however, the Worker Node-2 just got terminated due to auto scaling strategy or any replacement due to upgrade, caused the connection lost.
Let’s say if you try to remove the encapsulation layer of the Kubernetes networking design and make thing more easier based on the AWS supported CNI Plugin (Only rely on the ELB to forward the traffic to the Pod directly by using IP mode with annotation setting alb.ingress.kubernetes.io/target-type: ip in my Ingress object), you can see the downtime more obvious when Pod doing RollingUpdate. That’s because not only the problem we mentioned the issues in case (1)/(2)/(3), but also there has different topic on the behavior of the controller need to be covered if the question comes to zero downtime deployment:
Here is an example by using IP mode (alb.ingress.kubernetes.io/target-type: ip) as resgistration type to route traffic directly to the Pod IP
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: game-2048
name: ingress-2048
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service-2048
port:
number: 80
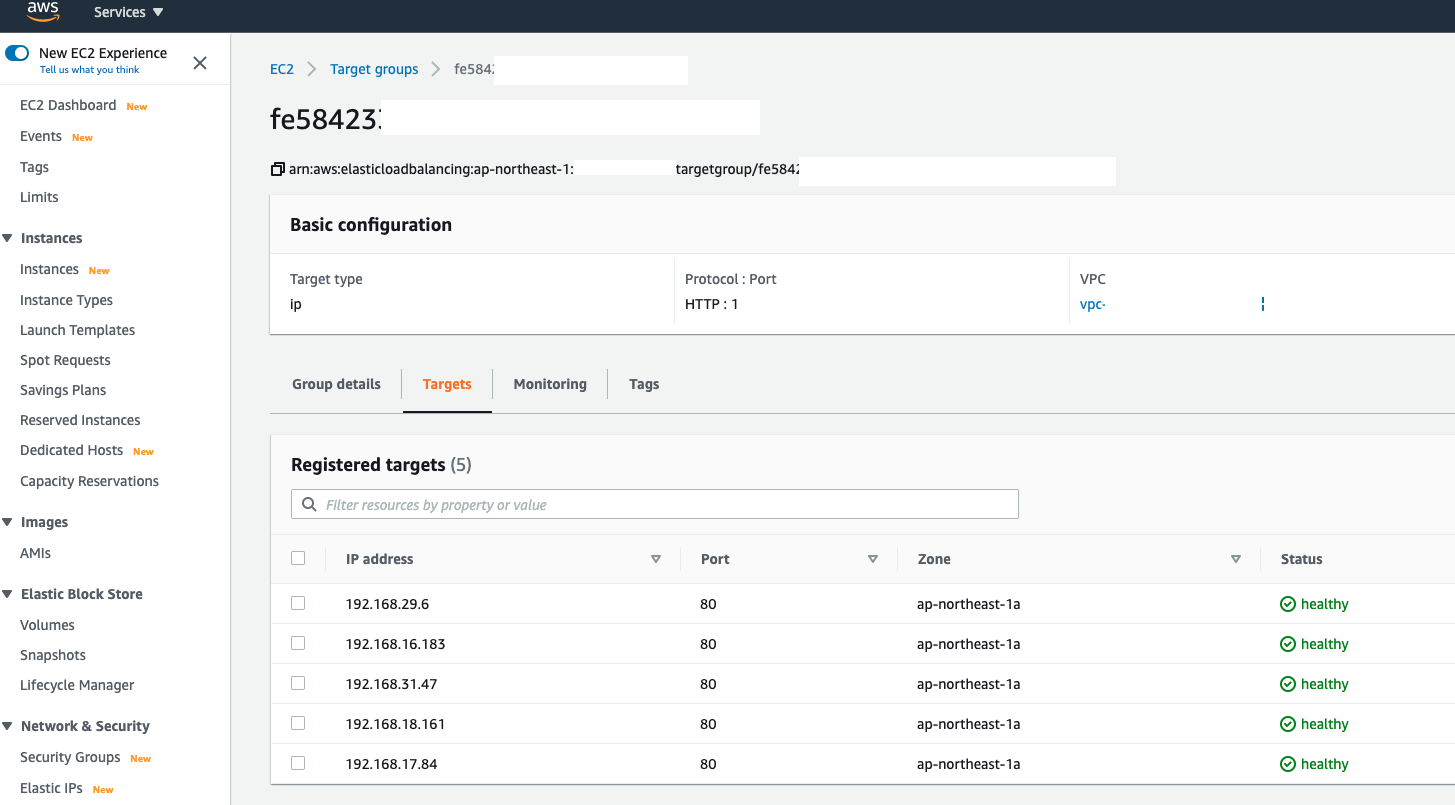
Again follow the issue we mentioned (1) (2) (3), when doing the rolling update (I was replacing the image again in IP mode), similar problem can be observed. Potentially, you can have 10-15 seconds even longer downtime can be noticed if you are doing the same lab:
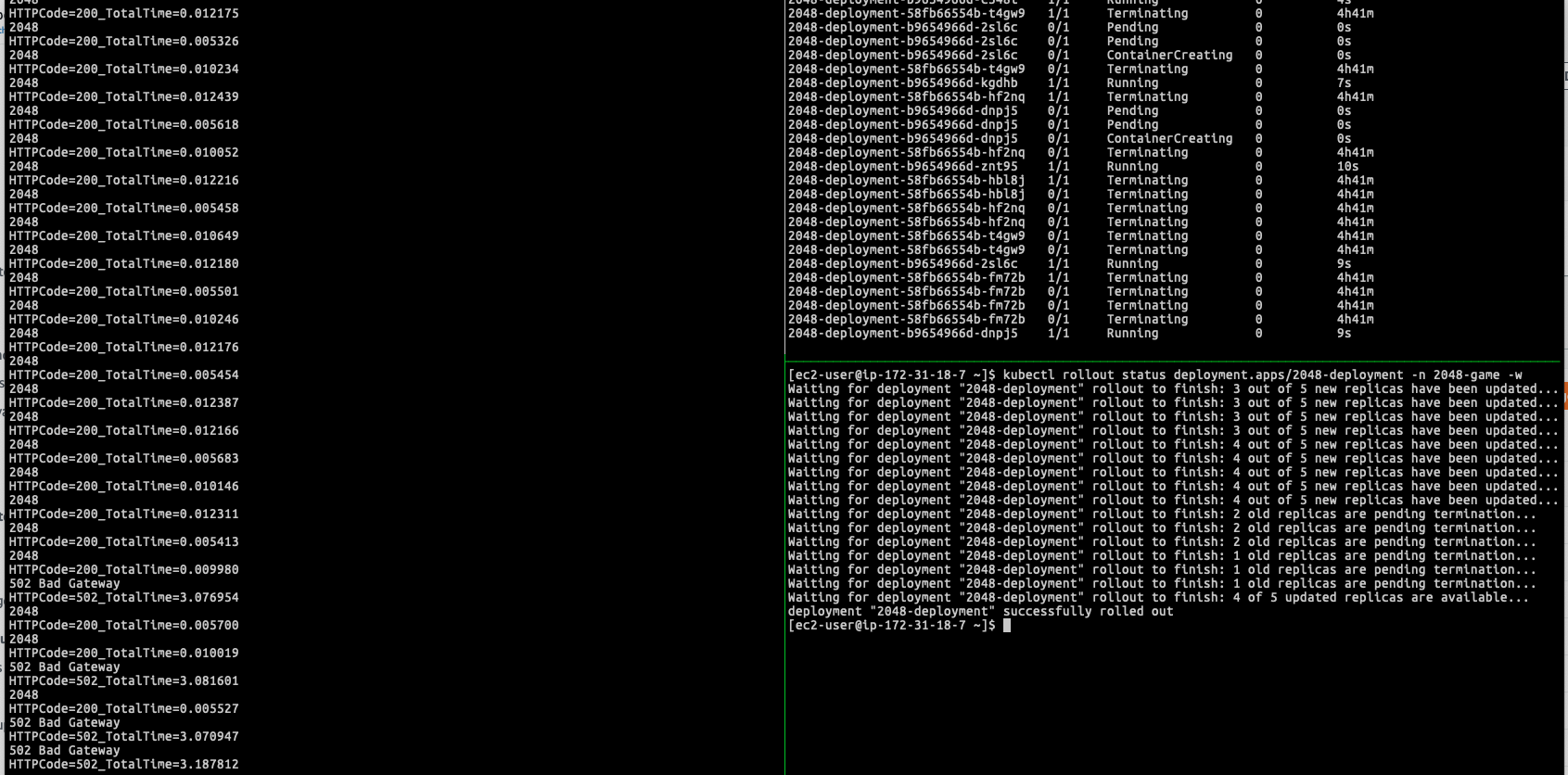
When Kubernetes is rolling the deployment, in the target group, you will see AWS Load Balancer Controller was issuing old targets draining process(Old Pods) in the meantime
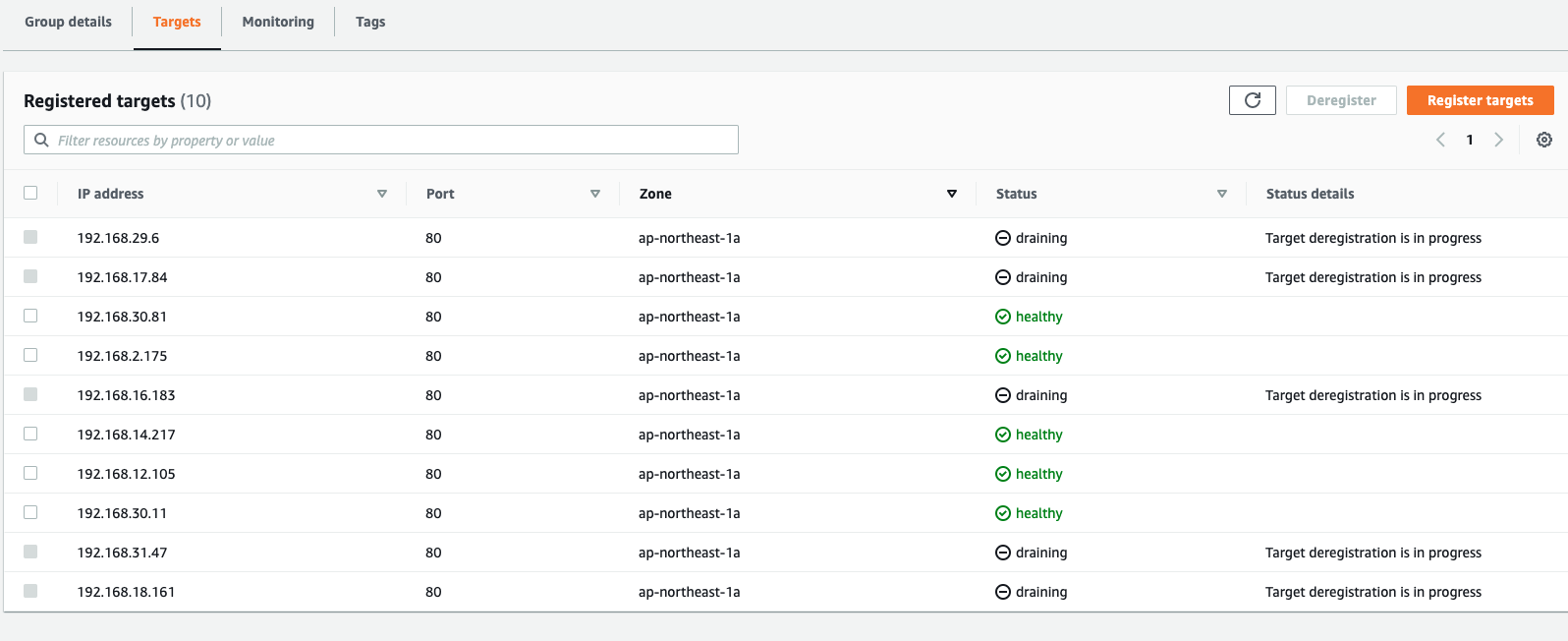
However, you still can see HTTP 502/504 errors exceed 3-10 seconds for a single requset
HTTPCode=200_TotalTime=0.005413
2048
HTTPCode=200_TotalTime=0.009980
502 Bad Gateway
HTTPCode=502_TotalTime=3.076954
2048
HTTPCode=200_TotalTime=0.005700
2048
HTTPCode=200_TotalTime=0.010019
502 Bad Gateway
HTTPCode=502_TotalTime=3.081601
2048
HTTPCode=200_TotalTime=0.005527
502 Bad Gateway
HTTPCode=502_TotalTime=3.070947
502 Bad Gateway
HTTPCode=502_TotalTime=3.187812
504 Gateway Time-out
HTTPCode=504_TotalTime=10.006324
Welcome to nginx!
HTTPCode=200_TotalTime=0.011838
Welcome to nginx!
The issue and the workflow of the AWS Load Balancer Controller
Let’s use this scenario as it is a edge problem we need to consider for most use case. The issue generally is bringing out the core topic we want to address and giving a good entry point to dive deep into the workflow between the Kubernetes, AWS Load Balancer Controller and the ELB, which can lead HTTP status code 502/503(5xx) erros during deployment when having Pod termination.
Before diving into it, we need to know when a pod is being replaced, AWS Load Balancer Controller will register the new pod in the target group and removes the old Pods. However, at the same time:
- For the the new Pods, the target is in
initialstate, until it pass the defined health check threshold (ALB health check) - For the old Pods is remaining as
drainingstate, until it completes draining action for the in-flight connection, or reaching out theDeregistration delaydefined in the target group.
Which result in the service to be unavailable and return HTTP 502.
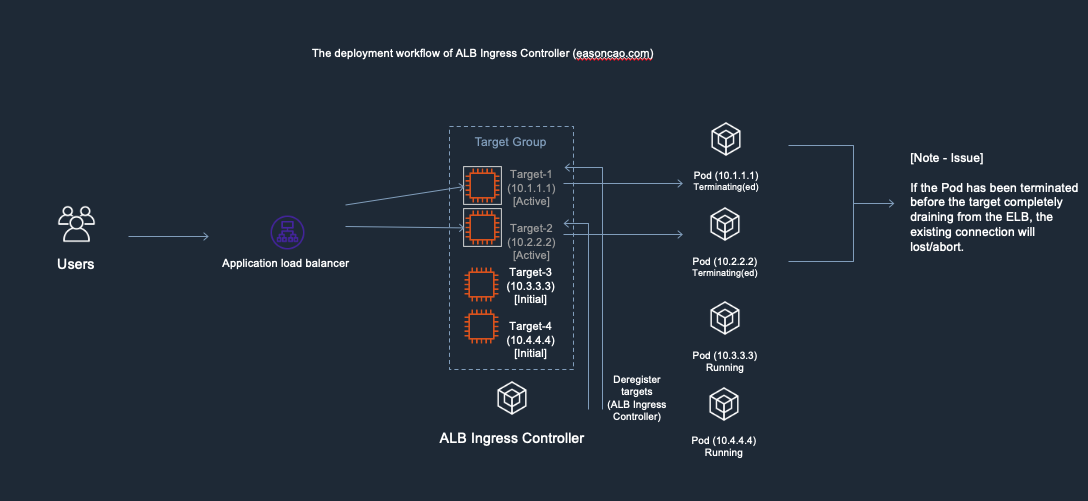
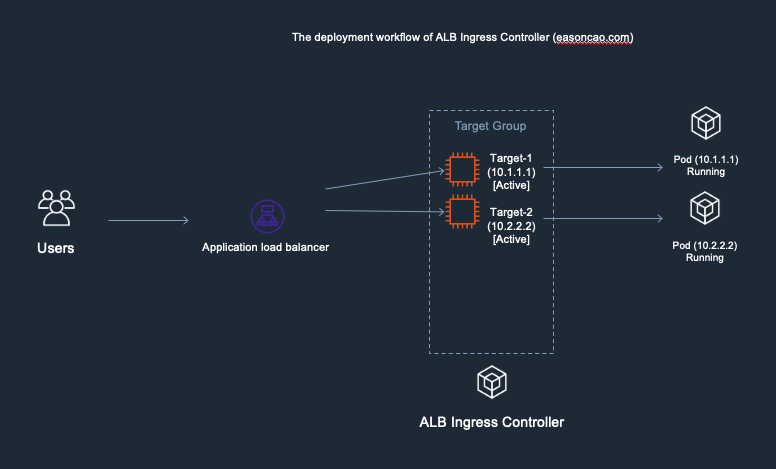
To better understand that, I made the following diagrams. It might be helpful to you understanding the workflow:
1) In the diagram, I used the following IP addresses to remark and help you recognize new/old Pods. Here is the initial deployment.
- Old Pods: Target-1(Private IP: 10.1.1.1), Target-2(Private IP: 10.2.2.2)
- New Pods: Target-3(Private IP: 10.3.3.3), Target-4(Private IP: 10.4.4.4)
2) At this stage, I was doing container image update and start rolling out the new copies of Pods. In the meantime, the controller will make RegisterTarget API call to ELB on behalf of the Kubernetes.
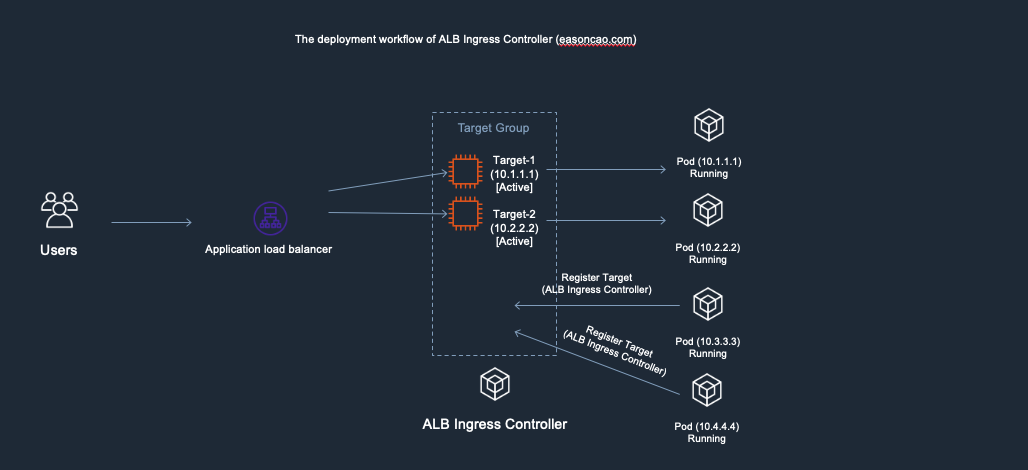
3) Meanwhile, the DeregisterTarget API will be called by AWS Load Balancer Controller and new targets are in initial state.
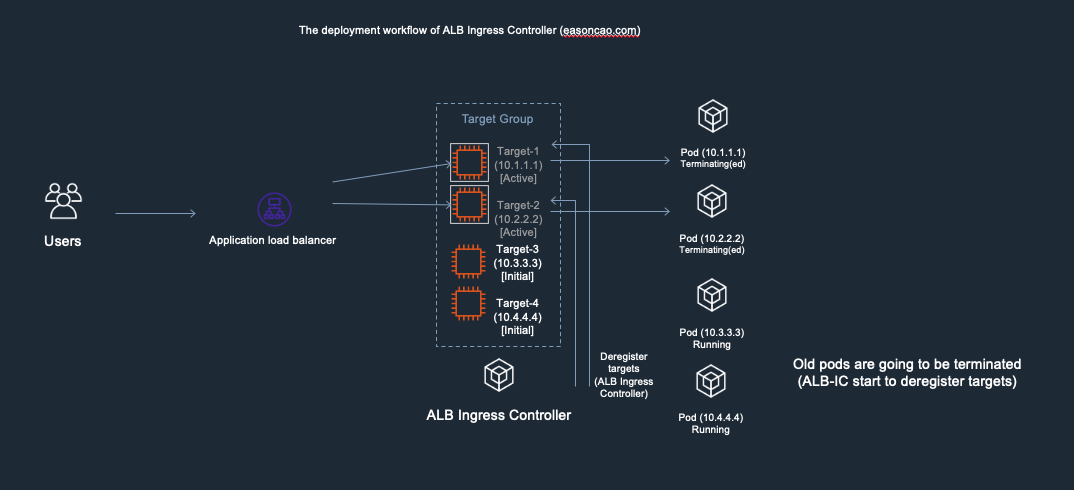
4) At this stage, anything could happen to cause service outage. Because the DeregisterTarget API call might take some time to process, but, Kubernetes doesn’t have any design to monitor the current state of the ELB Target Group, it only care about rolling the new version of Pods and terminate old one.
In this case, if the Pod got terminated by Kubernetes but Target-1 or Target-2 are still leaving in the ELB Target Group as Active/Healthy state (It need to wait few seconds to be Unhealthy once it reach out to the threshold of ELB HTTP health check), result in the ELB cannot forward the front-end request to the backend correctly.
5) ELB received the DeregisterTarget request. So the ELB Target Group will start to perform connection draining(set old targets as draining), and mark the Target-1/Target-2 as draining state, any new connection won’t be routed to these old targets.
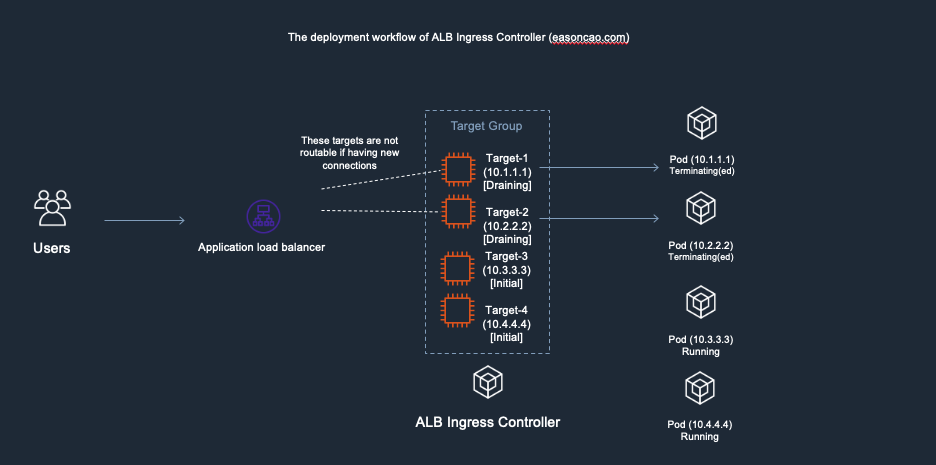
6) However, here brings another issue: if the new targets (Target-3 and Target-4) are still working on passing the health check of ELB(Currently those are in Initial state), there has no backend can provide service at this moment, which can cause the ELB only can return HTTTP 5XX status code
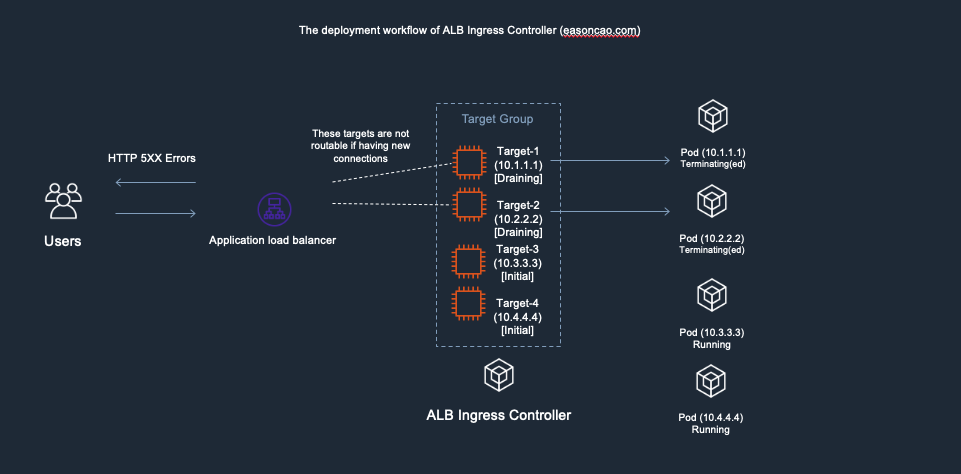
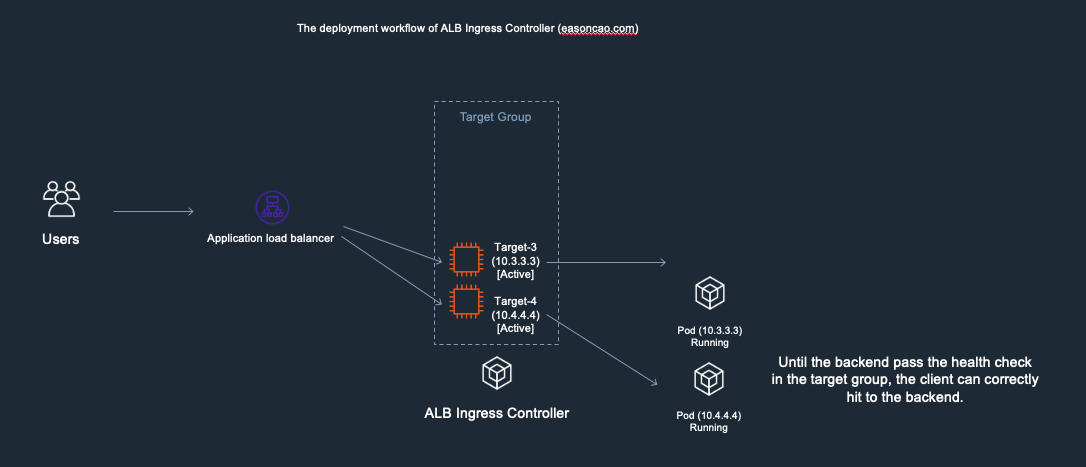
7) Until the new Pods is in Running state as well as can react the health check reqeust from ELB through HTTP/HTTPS protocol, the ELB end up mark the targets as Active/Healthy and the service become available
How to resolve the issue and meet zero-downtime?
Factor-1: Pod Readiness Gates
Since version v1.1.6, AWS Load Balancer Controller (ALB Ingress Controller) introduced Pod readiness gates. This feature can monitor the rolling deployment state and trigger the deployment pause due to any unexpected issue(such as: getting timeout error for AWS APIs), which guarantees you always have Pods in the Target Group even having issue on calling ELB APIs when doing rolling update.
ALB Ingress Controller 1.x (Legacy)
As mentioned in the previous workflow, obviously, if you would like to prevent the downtime, it is required to use several workarounds to ensure the Pod state consistency between ALB, ALB Ingress Controller and Kubernetes.
In the past, the readiness gate can be configured with legacy (version 1) by using the following pod spec. Here is an example to add a readiness gate with conditionType: target-health.alb.ingress.k8s.aws/<ingress name>_<service name>_<service port>
(As it might be changed afterward, for more detail, please refer to the documentation as mentioned in the AWS Load Balancer Controller project on GitHub):
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
clusterIP: None
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/scheme: internal
spec:
rules:
- http:
paths:
- backend:
serviceName: nginx-service
servicePort: 80
path: /*
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
readinessGates:
- conditionType: target-health.alb.ingress.k8s.aws/nginx-ingress_nginx-service_80
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
AWS Load Balancer Controller (After v2.x)
For now, if you are using controller later than v2, the readiness gate configuration can be automatically injected to the pod spec by defining the label elbv2.k8s.aws/pod-readiness-gate-inject: enabled to your Kubernetes namespace.
$ kubectl create namespace readiness
namespace/readiness created
$ kubectl label namespace readiness elbv2.k8s.aws/pod-readiness-gate-inject=enabled
namespace/readiness labeled
$ kubectl describe namespace readiness
Name: readiness
Labels: elbv2.k8s.aws/pod-readiness-gate-inject=enabled
Annotations: <none>
Status: Active
So defining legacy fields readinessGates and conditionType are not required if you are using controller later than v2.0. If you have a pod spec with legacy readiness gate configuration, ensure you label the namespace and create the Service/Ingress objects before applying the pod/deployment manifest. The controller will remove all legacy readiness-gate configuration and add new ones during pod creation.
Factor-2: Graceful shutdown your applications
For existing connections(As mentioned in the workflow-4), the case is involving the gracefully shutdown/termination handling in Kubernetes. Therefore, it is requires to use the method provided by Kubernetes.
You can use Pod Lifecycle with preStop hook and make some pause(like using sleep command) for Pod termination. This trick ensures ALB can have some time to completely remove old targets on Target Group (It is recommended to adjust longer based on your Deregistration delay):
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 40"]
terminationGracePeriodSeconds: 70
Note: If a container has a preStop hook configured, that runs before the container enters the Terminated state. Also, if the preStop hook needs longer to complete than the default grace period allows, you must modify
terminationGracePeriodSecondsto suit this.
An example to achieve zero downtime when doing rolling update after applying methods above
First apply the label to the namespace so the controller can automatically inject the readiness gate:
apiVersion: v1
kind: Namespace
metadata:
name: 2048-game
labels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled
apiVersion: apps/v1
kind: Deployment
metadata:
name: "2048-deployment"
namespace: "2048-game"
spec:
selector:
matchLabels:
app: "2048"
replicas: 5
template:
metadata:
labels:
app: "2048"
spec:
# This would be optional if you are using controller after v2.x
readinessGates:
- conditionType: target-health.alb.ingress.k8s.aws/2048-ingress_service-2048_80
terminationGracePeriodSeconds: 70
containers:
- image: alexwhen/docker-2048
imagePullPolicy: Always
name: "2048"
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 40"]
Here is an example after following the practice I was getting a try. The deployment will apply the feature and can see the status of the readiness gates:
$ kubectl get pods -n 2048-game -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
2048-deployment-99b6fb474-c97ht 1/1 Running 0 78s 192.168.14.209 XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.compute.internal <none> 1/1
2048-deployment-99b6fb474-dcxfs 1/1 Running 0 78s 192.168.31.47 XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.compute.internal <none> 1/1
2048-deployment-99b6fb474-kvhhh 1/1 Running 0 54s 192.168.29.6 XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.compute.internal <none> 1/1
2048-deployment-99b6fb474-vhjbg 1/1 Running 0 54s 192.168.18.161 XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.compute.internal <none> 1/1
2048-deployment-99b6fb474-xfd5q 1/1 Running 0 78s 192.168.16.183 XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.compute.internal <none> 1/1
Once rolling the new version of the container image, the deployment goes smoothly and prevent the downtime issue as mentioned in previous paragraphs:
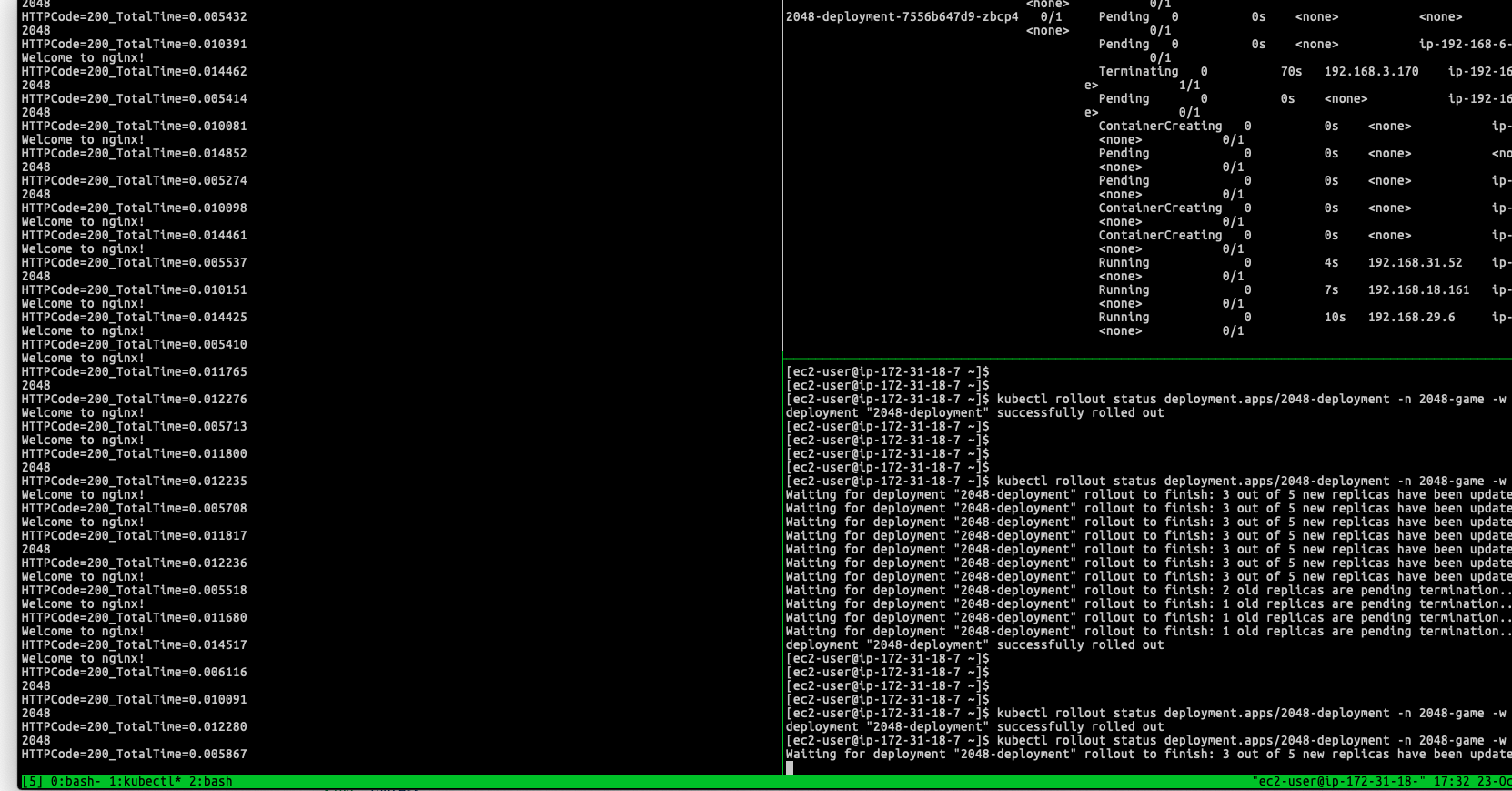
In my scenario, the Kubernetes need to take at least 40 seconds termination period for single Pod, so the old targets are gradually moved out instead of remove all of them at once within few seconds, until entire target group only exists new targets.
Therefore, you probably also need to notice the Deregistration delay defined in your ELB Target Group, which can be updated through the annotation:
alb.ingress.kubernetes.io/target-group-attributes: deregistration_delay.timeout_seconds=30
In this case, it is recommended to be less than 40 seconds so ELB can drain your old targets before the Pod completely shutdown.
With the configuration, client can get normal responses from old Pods/existing connection during the deployment:
HTTPCode=200_TotalTime=0.012028
2048
HTTPCode=200_TotalTime=0.005383
2048
HTTPCode=200_TotalTime=0.010174
2048
HTTPCode=200_TotalTime=0.012233
Welcome to nginx!
HTTPCode=200_TotalTime=0.007116
2048
HTTPCode=200_TotalTime=0.010090
2048
HTTPCode=200_TotalTime=0.012201
2048
HTTPCode=200_TotalTime=0.005532
2048
HTTPCode=200_TotalTime=0.010107
2048
HTTPCode=200_TotalTime=0.012163
Welcome to nginx!
HTTPCode=200_TotalTime=0.005452
Welcome to nginx!
HTTPCode=200_TotalTime=0.009950
2048
HTTPCode=200_TotalTime=0.012082
Welcome to nginx!
HTTPCode=200_TotalTime=0.005349
2048
HTTPCode=200_TotalTime=0.010142
2048
HTTPCode=200_TotalTime=0.012143
2048
HTTPCode=200_TotalTime=0.005507
...
HTTPCode=200_TotalTime=0.012149
Welcome to nginx!
HTTPCode=200_TotalTime=0.005364
Welcome to nginx!
HTTPCode=200_TotalTime=0.010021
Welcome to nginx!
HTTPCode=200_TotalTime=0.012092
Welcome to nginx!
HTTPCode=200_TotalTime=0.005463
Welcome to nginx!
HTTPCode=200_TotalTime=0.010136
Welcome to nginx!
This is the practice in case having AWS Load Balancer Controller for doing graceful deployment with RollingUpdate. However, it is another big topic need to be discussed regarding what type of the application when rolling the update. Because other type of applications need to establish long connection with the ELB or have requirement for considering persistence data need to be stored on the backend. All these things can bring out other issues we need to talk about.
But in summarize, with the deployment strategy above, it is also recommended to design the client/backend application as stateless, implement retry and fault-tolerance. These mothod usually help to reduce the customer complain and provide better user experience for most common use case.
Conclusion
Due to the current design of Kubernetes, it is involving the state inconsistent issue when you are exposing the service with Application Load Balancer. Therefore, in this article, I mentioned the potential issue when doing rolling update in the scenario having container service integrating with the AWS Load Balancer Controller (ALB Ingress Controller).
Even the technology is always in revolution, I am still willing to help people better handle the deployment strategy. I used a couple of hours to draft this content and tried to cover several major issues, metioned things you might need to aware, break down the entire workflow and shared few practical suggestions that can be achieved by using AWS Load Balancer Controller in order to meet the goal when doing zero downtime deployment.
The article was written based on my own experience (Of course many communications back and forth with different customers using AWS), it might not be perfect but I hope it is helpful to you. For sure, if you find any typo or have any suggestions, please feel free and leave comment below.
References
Share on
Twitter Facebook LinkedInIs that useful? Let me know or buy me a coffee
 一次性支持 (ECPay)
一次性支持 (ECPay)


Leave a comment